
中国文字的简化,是二十世纪五十年代中期,中国大陆政府在周恩来总理的直接主持关心下,结合了上百名专家,对数千个常用的中国文字进行了一次字体的简化。简化文字,目的就是为了让数以亿计的人民大众,能够尽早尽快地识字认字,提高使用文字的速度,提升文化水平,方便学生在校学习,以此为最基本的基础,才有可能学习科技,建立一个富强的国家。
汉字自古以来就有繁体与简体两套写法,后来经过篆体隶化,并存两种写法的文字越来越多。由六朝到隋唐,汉字逐渐隶楷化,很多古字都增加笔画,而简体字开始被称为"俗体"、"小写"、"破字"等,在民间社会仍广为流传。

繁化和简化的字,在古代就已存在。有些人造新字,后来就通行使用。中国文字在秦始皇统一文字之后,随著时代改变,出现了繁体、简体、俗体、异体等字。官方的文书,这段期间,民间文字的使用多是采约定成俗的方式,一直到太平天国时期,才开始文字的简化。
中国考古界先后发布了一系列较殷墟甲骨文更早、与汉字起源有关的出土资料,改写了中国文字史。贾湖刻符经碳14物理测定,距今约7762年(±128年)历。
还有七千年前的双墩刻符、六千年前的半坡陶符、五千多年前青墩遗址刻符、连字成句的庄桥坟遗址文字、大汶口陶尊符号、尧舜时代的陶寺遗址朱文、夏墟的水书。早期的骨刻文就是丰富的文字系统,后期的超越了起源史,属于初步成熟阶段了。
扩展资料
汉字是承载文化的重要工具,当前留有大量用汉字书写的典籍。不同的方言、甚至语言都使用汉字作为共同书写体系。在古代日本、朝鲜半岛、越南、琉球群岛,以及位于婆罗洲的兰芳共和国,汉字都曾是该国正式文书的唯一系统,因而汉字在历史上对文明的传播分享有着重要作用。
由于汉字和发声的联系不是非常密切,比较容易被其他民族所借用,如日本、朝鲜半岛和越南都曾经有过不会说汉语,单纯用汉字书写的历史阶段。汉字的这个特点对于维系一个文化圈—一个充满各种互相不能交流的方言群体的民族——发挥了主要的作用。
-汉字
中文
中文——作为一个民族的母语,中文是当今世界流行语言体系里最大的一个分支。始创于公元前黄帝在世的时代,成就于公元二十世纪后期。是一种发源最早而成熟最晚的一个语言体系。是东方文明的一种标志与成果,是人类用来精确命名与定义万事万物的一种重要信息载体。体系包括几千个常用单字和上万个字词成语,是文明社会不可缺少的重要组成。 自【一名京人】编辑
从20世纪50年代初机器翻译课题被提出算起,自然语言处理(NLP)的研发历史至少也有50年了。90年代初,NLP的研究目标开始从小规模受限语言处理走向大规模真实文本处理。把这个新目标正式列入大会主题的是1990年在赫尔辛基举行的“第13届国际计算语言学大会”。那些只有几百个词条和数十条语法规则的受限语言分析系统,通常被业内人士戏称为“玩具”,不可能有什么实用价值。政府、企业和广大计算机用户期盼的是像汉字输入、语音听写机、文-语转换(TTS)、搜索引擎、信息抽取(IE)、信息安全和机器翻译(MT)那样的、有能力处理大规模真实文本的实用化系统。
正是基于对这个里程碑式转折的关注,笔者在1993年就列举了四种大规模真实文本处理的应用前景:新一代信息检索系统;按客户要求编辑的报纸;信息抽取,即把非结构化的文本转化为结构化的信息库;大规模语料库的自动标注。值得庆幸的是,今天所有这四个方向都有了实用化或商品化的成果。
尽管全世界都把大规模真实文本处理看做是NLP的一个战略目标,但这不等于说受限领域的机器翻译、语音对话、电话翻译和其他一些基于深层理解的自然语言分析技术或理论研究,就不应当再搞了。目标和任务的多样化是学术界繁荣昌盛的一个标志。问题是要考虑清楚NLP的主战场在哪里,我们的主力应当部署在哪里。
中文难办吗?
谈到中文信息处理所面临的重大应用课题,如企业和广大计算机用户所期盼的汉字输入、语音识别等,大家似乎并没有什么分歧。但是当讨论深入到实现这些课题的方法或技术路线时,分歧马上就泾渭分明了。第一种意见认为,中文信息处理的本质是汉语理解,也就是要对汉语真实文本实施句法-语义分析。持这种意见的学者主张,以往在中文信息处理中使用的概率统计方法已经走到了尽头,为了在理解或语言层面上解决中文信息处理问题,就必须另辟蹊径,这条蹊径便是语义学。据说这是因为汉语不同于西方语言,汉语的句法相当灵活,汉语本质上是一种意合语言等。
与上述意见相对立的观点是:前面提到的绝大多数应用系统(MT除外)其实都是在没有句法-语义分析的情况下实现的,因此谈不上“理解”。 如果一定要说“理解”,那么只是用图灵实验来证实的所谓“理解”。
上述双方争论的焦点是方法,但目标和方法通常是密不可分的。如果我们同意把大规模真实文本处理作为NLP的战略目标,那么实现这一目标的理论和方法也必然要跟着变化。无独有偶,1992年在蒙特利尔召开的“第四届机器翻译的理论和方法国际会议(TMI-92)”宣布大会的主题是“机器翻译中的经验主义和理性主义方法”。这就是公开承认,在传统的基于语言学和人工智能方法(即理性主义)的NLP技术以外,还有一种基于语料库和统计语言模型的新方法(即经验主义)正在迅速崛起。
NLP的战略目标和相应的语料库方法都是从国际学术舞台的大视野中获得的,中文信息处理自然也不例外。那种认为中文文本处理特别困难,以至要另辟蹊径的观点,缺少有说服力的事实根据。拿信息检索(IR)来说,它的任务是从一个大规模的文档库中寻找与用户的查询相关的文档。怎样表示文档和查询的内容,以及如何度量文档和查询之间的相关程度,就成为IR技术需要解决的两个基本问题。召回率和精确率则是评价一个IR系统的两个主要指标。由于文档和查询都是用自然语言表述的,这个任务可以用来说明中文和西方语言所面临的问题和所采用的方法其实是十分相似的。一般来说,各文种的IR系统都用文档和查询中的词频(tf)和倒文档频率(idf)来表示文档和查询的内容,所以本质上是一种统计方法。
世界文本检索大会TREC ( 和 W = w1...wn分别代表词类标记序列和词序列,则词性标注任务可视为在已知词序列W的情况下,计算如下条件概率极大值的问题:
C*= argmaxC P(C|W)
= argmaxC P(W|C)P(C) / P(W)
≈ argmaxC ∏i i=1,...,nP(wi|ci)P(ci|ci-1 )
P(C|W) 表示:已知输入词序列W的情况下,出现词类标记序列C的条件概率。数学符号argmaxC 表示通过考察不同的候选词类标记序列C, 来寻找使条件概率P(C|W) 取最大值的那个词序列W*。后者应当就是对W的词性标注结果。
公式第二行是利用贝叶斯定律转写的结果,由于分母P(W) 对给定的W是一个常数,不影响极大值的计算,故可以从公式中删除。接着对公式进行近似。首先,引入独立性假设,认为词序列中的任意一个词wi的出现概率近似,只同当前词的词性标记ci有关,而与周围(上下文)的词类标记无关。即词汇概率
P(W|C) ≈ ∏i i=1,...,nP(wi|ci )
其次,采用二元假设,即近似认为任意词类标记 ci的出现概率只同它紧邻的前一个词类标记ci-1有关。因此有:
P(C) ≈∏i i=,...,n P(ci|ci-1)
P(ci|ci-1) 是词类标记的转移概率,也叫做二元模型。
上述这两个概率参数也都可以通过带词性标记的语料库来分别估计:
P(wi|ci) ≈ count(wi,ci) / count(ci)
P(ci|ci-1) ≈ count(ci-1ci) / count(ci-1)
顺便指出,国内外学者用词类标记的二元或三元模型实现的中、英文词性自动标注都达到了约95%的标注精确率。
评测为什么是惟一的评判标准
有评测才会有鉴别。评判一种方法优劣的惟一标准是相互可比的评测,而不是设计人员自己设计的“自评”,更不是人们的直觉或某个人的“远见”。近年来,在语言信息处理领域,通过评测来推动科学技术进步的范例很多。国家“863计划”智能计算机专家组曾对语音识别、汉字(印刷体和手写体)识别、文本自动分词、词性自动标注、自动文摘和机器翻译译文质量等课题进行过多次有统一测试数据和统一计分方法的全国性评测,对促进这些领域的技术进步发挥了非常积极的作用。
在国际上,美国国防部先后发起的TIPSTER 和 TIDES两个和语言信息处理相关的计划,就被称为“评测驱动的计划”。它们在信息检索(TREC)、信息抽取(MUC)、命名实体识别(MET-2)等研究课题上,既提供大规模的训练语料和测试语料,又提供统一的计分方法和评测软件,以保证每个研究小组都能在一种公平、公开的条件下进行研究方法的探讨,推动科学技术的进步。TREC、MUC和MET-2等会议所组织的多文种评比活动也有力地说明,其他语言采用并证明有效的方法,对中文也一样适用,不同文种应用系统的性能指标大体相当。固然,每种语言都有它自己的个性,然而这些个性不应当被用来否定语言的共性,并在事实不足的情况下做出错误的判断。
为了推动中文信息处理的发展,让我们拿起评测这个武器,扎扎实实地研究其适用技术,不要再想当然了。建议政府科研主管部门在制定项目计划时,至少要在一个项目的总经费中拿出10%左右的拨款用于资助该项目的评测。没有统一评测的研究成果,终究不是完全可信的
分类:教育/科学 >> 科学技术
解析:
1950年,中央人民 *** 教育部社会教育司编制《常用简体字登记表》。
1951年,在上表的基础上,根据“述而不作”的原则,拟出《第一批简体
字表》,收字555个。
1952年2月5日,中国文字改革研究委员会成立。
1954年底,文改委在《第一批简体字表》的基础上,拟出《汉字简化方案
〔草案〕》,收字798个,简化偏旁56个,并废除400个异体字。
1955年2月2日,《汉字简化方案〔草案〕》发表,把其中的261个字
分3批在全国50多种报刊上试用。同年7月13日,国务院成立汉字简化方案审
订委员会。同年10月,举行全国文字改革会议,讨论通过《汉字简化方案〔修正
草案〕》,收字减少为515个,简化偏旁减少为54个。
1956年1月28日,《汉字简化方案》经汉字简化方案审订委员会审订,
由国务院全体会议第23次会议通过,31日在《人民日报》正式公布,在全国推
行。以后这个方案根据使用情况而略有改变,1964年5月,文改委出版了《简
化字总表》,共分三表:第一表是352个不作偏旁用的简化字,第二表是132
个可作偏旁用的简化字和14个简化偏旁,第三表是经过偏旁类推而成的1754
个简化字;共2238字(因“签”、“须”两字重见,实际为2236字),这
就是今天中国大陆的用字标准。
汉字的起源从仓颉造字的古老传说到100多年前甲骨文的发现,历代中国学者一直致力于揭开汉字起源之谜。关于汉字的起源,中国古代文献上有种种说法,如“结绳”、“八卦”、“图画”、“书契”等,古书上还普遍记载有黄帝史官仓颉造字的传说。现代学者认为,成系统的文字工具不可能完全由一个人创造出来,仓颉如果确有其人,应该是文字整理者或颁布者。最早刻划符号距今8000多年最近几十年,中国考古界先后发布了一系列较殷墟甲骨文更早、与汉字起源有关的出土资料。这些资料主要是指原始社会晚期及有史社会早期出现在陶器上面的刻画或彩绘符号,另外还包括少量的刻写在甲骨、玉器、石器等上面的符号。可以说,它们共同为解释汉字的起源提供了新的依据。通过系统考察、对比遍布中国各地的19种考古学文化的100多个遗址里出土的陶片上的刻划符号,郑州大学博士生导师王蕴智认为,中国最早的刻划符号出现在河南舞阳贾湖遗址,距今已有8000多年的历史。作为专业工作者,他试图通过科学的途径比如综合运用考古学、古文字构形学、比较文字学、科技考古以及高科技手段等一些基本方法,进一步对这些原始材料做一番全面的整理,从而爬梳排比出商代文字之前汉字发生、发展的一些头绪。然而情况并不那么简单,除了已有郑州商城遗址、小双桥遗址(该遗址近年先后发现10余例商代早期朱书陶文)的小宗材料可以直接和殷墟文字相比序之外,其它商以前的符号则零星分散,彼此缺环较多,大多数符号且与商代文字构形不合。还有一些符号地域色彩较重、背景复杂。汉字体系正式形成于中原地区王蕴智认为,汉字体系的正式形成应该是在中原地区。汉字是独立起源的一种文字体系,不依存于任何一种外族文字而存在,但它的起源不是单一的,经过了多元的、长期的磨合,大概在进入夏纪年之际,先民们在广泛吸收、运用早期符号的经验基础上,创造性地发明了用来记录语言的文字符号系统,在那个时代,汉字体系较快地成熟起来。据悉,从考古发掘的出土文字资料来看,中国至少在虞夏时期已经有了正式的文字。如近年考古工作者曾经在山西襄汾陶寺遗址所出的一件扁陶壶上,发现有毛笔朱书的“文”字。这些符号都属于早期文字系统中的基本构形,可惜这样的出土文字信息迄今仍然稀少。文字最早成熟于商代就目前所知和所见到的殷商文字资料来说,文字载体的门类已经很多。当时的文字除了用毛笔书写在简册上之外,其他的主要手段就是刻写在龟甲兽骨、陶器、玉石上以及陶铸在青铜器上。商代文字资料以殷墟卜用甲骨和青铜礼器为主要载体,是迄今为止中国发现的最早的成熟文字。殷墟时期所反映出来的商代文字不仅表现在字的数量多,材料丰富,还突出地表现在文字的造字方式已经形成了自己的特点和规律。商代文字基本字的结体特征可分为四大类:取人体和人的某一部分形体特征为构字的基础;以劳动创造物和劳动对象为构字的基础;取禽兽和家畜类形象为构字的基础;取自然物象为构字的基础。从构形的文化内涵上来考察,这些成熟较早的字形所取裁的对象与当初先民们的社会生活相当贴近,具有很强的现实性的特征。同时,这些字形所描写的内容涉及到了人和自然的各个层面,因而还具有构形来源广泛性的特征。参考资料:人民网-人民日报发言时间:11-921:06文字的使用,是人类文明一大进步。汉字以象形文字为特征而在人类语林中独树一帜,它在文字、语言上的优点,也正在为使用表音文字的人们所认识和接受。汉字起源于何时,又是谁创造的,至今并没有一致的说法。《世本》、《荀子》、《吕氏春秋》、《韩非子》等古文献,都说汉字是在黄帝时代由仓颉、沮诵两人创造的。许慎《说文解字》试图作出比较圆通的解释,认为伏羲作八卦“以垂宪象”,启发人们根据不同事物去作不同的符号。神农氏时代“结绳而治”,但庶事繁多,终于不能满足。在黄帝时代就出现了仓颉,,“见鸟兽蹄选之迹,知分理之可相别异也,初造书契”;并说仓颉初造书契时,“依类象形”谓之文,后来形声相益谓之字。经过长期演迸发展,总结成构成汉字的六种方法,称为“六书”,即“指事、象形、形声、会意,、转注、假借”。《元命苞》则说,仓颉仰观星象圆曲之势,俯察龟纹、鸟羽、山川,甚至手掌纹路等,都是他据以创作文字的基础。在近代文字学建立以前,《说文解字》有关汉字起源的学说,无疑是最权威的。’然而,《尚书孔传》和《拾遗记》则说伏羲造书契以代结绳,文籍也在他那个时代兴起,这显然要比黄帝时代早得多了。·在疑古思潮的影响下,《经学六变记》提出另一种看法,认为汉字实际上是孔子亲手制定的。幸好此书流传不广,而且用—骨文的发现迅速粉碎了这种神化孔子的说法;甲骨文韵设现也动摇了《说文解字》有关文字起源酌传说:对传说的“六书”理论也提出了各种质疑。随着仰韶文化陶器记事符号的发现,不少专家认为那是具有汉字性质的符号。根据考古发现,龙山文化、大汶口文化、良渚文化和二里头文化中出土了一大批带有记事符号的陶器,有些确实非常接近于文字,特别是大汶口文化陶符等图形被释读为斤、戌、炅、炅山或斧、锛、旦等,于是人们认为中国文字起源于陶器刻符。然而,平心而论,现有陶符接近汉字的还不多,而且能释读的更少,汉字起源于陶刻符号的结论似乎过早,不过陶刻符号的发现和释读,毕竟使人们看到了解决汉字起源问题的曙光,人们寄希望于有的出土资料和的研究成果。发言时间:11-820:43造字原理:六书是汉字组字的基本原理,在周礼中就有提到了六书,只是没有说明具体内容。到了东汉,许慎在《说文解字》中,详细阐述了“六书”这个汉字构造原理:象形、指事、会意、形声、转注、假借。象形:这种造字法是依照物体的外貌特征来描绘出来,所谓画成其物,随体诘诎是也。如日、月、山、水等四个字,最早就是描绘日、月、山、水之图案,后来逐渐演化变成现在的造型。指事:这是指表现抽象事情的方法,所谓“各指其事以为之”是也。如卜在其上写作“上”,人在其下写作“下”。形声:此乃文字内以特定形状(字根)表特有的音。例如:胡,这个字也可为一个字根,结合不同的属性字根,可合成为:蝴、蝴、湖、葫、瑚、醐等等,而以同样的发音(也有的只有声母一样),表达不同的事物。但形声字,也因古今语言音韵变迁,不少古代同类形声字在今天的官话已无共同音素了。会意:这个造字法,是将两个字根组合起来,使衍生出新的含意。如“日”和“月”组起来,就是日光加月光变成“明”。“人”字和“言”字合成“信”字,意思就是人过去所言;有信,就是这个人都很遵守自己说过的话。转注:这是用于两个字互为注释,彼此同义而不同形,汉代许慎解释道:“建类一首,同意相受,考、老是也。”,这怎么说呢?此二字,古时“考”可作“长寿”讲,“老”、“考”相通,意义一致,即所谓老者考也,考者老也。诗经的《大雅•棫朴》亦云:“周王寿考。”。苏轼的《屈原塔诗》也有古人谁不死,何必较考折。一语。其中的““考”皆“老”意,特别注意的是,后代的文字学家针对许慎的前述的定义也作了大量的解释。其中包括“形转说、声转说、义转说”三类,只是这三种说法有人认为不够全面,当代古文字家林沄先生也有解释说“转注”就是一个形体(字根)记录两个读音和意义完全不同的两个词。例如“帚和妇”与甲骨文中的“母和女”等等。假借:这法简言之,借用一字,去表达别的事物。一般来说,是有一个无法描述的新事物,就借用一个发音接近或是属性近似的字根,来表达这个新事物。例如:“又”,本来是指右手(最早可见于甲骨文),但后来被假借当作“也是”的意思。闻,本意是用耳朵听东西的意思。例如《大学‧第七章》中有“视而不见,听而不闻,食而不知其味”,但后来被假借成嗅觉的动词(不过也有人认为这是错用)。总结以上六书,前两项,“造字法”也;中两项,“组字法”也;后两项,“用字法”也。这六个原理,是古代文字学学者归纳出来的字学理论。其所含汉字构成法则,是长期演化而成的,不是任何一个人独创的。汉字的结构:汉字由一个或以上的字根以二维方式(欧语系是一维文字)在特定的空间、配置在一个正方块内而组成,因此有方块字的别称,从结构上来看,汉字有以下特色:单一字内就有很高的信息密度,在表达同样的事物时,可比表音文字用更短的篇幅表达同样的讯息,所以汉字的阅读效率很高。一个汉字乃由四百多个表意象形字母为基本字根,如金、木、水、火、土等,像积木一样组合而成。一个未知文字的含意,可拆字,从组成字根以及空间的配置推断出其字义。当时代演进出现新事物难以词的方式来表达时,也能以字根组合原则,合成出新字来用,例如中文的铀字,就是近代为了表现一种新发现的化学元素而新造的字。汉字组成的字根空间配置对字义有影响:如同样是“心跟亡”的合体,左右排是“忙”,上下排是“忘”,排列不同,导致不同含义;文字右边有“乂”这个字的部件,这表示右手(手的左偏旁表示左手)持某物对左边字根作某事(金文、甲骨文考古的发现),如果右手上面拿东西就变成“攵”,有这个字根的,几乎都是攻击性或是用暴力达成某件事,例如攻、败、敲、收、散、政、牧、敕等等。字形(汉字书法):“国”这个字的笔画汉字有各种不同的书写方式,即有不同的字体;不同的字体,汉字的字形不一样。规整的字体(如楷书、宋体、隶书、篆书等)书写下的汉字是一种方块字,每个字占据同样的空间。汉字包括独体字和合体字,独体字不能分割,如“文”、“中”等;合体字由基础部件组合构成,占了汉字的90%以上。合体字的常见组合方式有:上下结构,如“笑”、“尖”;左右结构,如“词”、“科”;半包围结构,如“同”、“趋”;全包围结构,如“团”、“回”;复合结构,如“赢”、“斑”等。汉字的基础部件包括独体字、偏旁部首和其他不成字部件。汉字的最小构成单位是笔画。书写汉字时,笔画的走向和出现的先后次序,即“笔顺”,是比较固定的。基本规则是,先横后竖,先撇后捺,从上到下,从左到右,先外后内,先外后内再封口,先中间后两边。不同书写体汉字的笔顺可能有所差异。读音:汉字是多种方言的共同书写体系,每个字代表一个音节。中国大陆现今以普通话作为标准读音,普通话的音节由一个声母、一个韵母及声调确定,实际用到1300多个音节。由于汉字数目庞大,因而有明显的同音字现象;同时还有同一字多音的情形,称为多音字。这一情况在各种汉语中是普遍存在的。汉字虽然以表意为主,但并非没有表音成分,最常见的是人名、地名,其次就是外来词的音译,比如沙发。此外,还有部分原有的表音词,如(一命)“呜呼”、“哈哈”大笑等。但即使如此,还是有一定表意成分,特别是该国国内的人名、地名。而即使是国外的人名、地名,也存在某些表意的底线,比如“Bush”绝不能音译成“不死”。由于汉字本身不表音,自汉朝到20世纪汉字在数量上、写法上虽有变迁,但无法看出发音的变化。必须进行专门的研究才能推测它们在上古汉语和中古汉语的发音。有学者经研究认为:汉朝之前,一个汉字发音为两个音节,次要音节和主要音节,类似今日的韩、日语。详见上古汉语。汉字在日语中的读音有“音读”和“训读”之分,往往一个字有很多读法,原因来自中国不同时期传入日本的发音。在朝鲜语中则大致为一字一音,没有训读。除了日本以外,其他汉字使用国也有使用了一些多音节的字,如“里”(海里)、“嗧”(加仑)、“瓩”(千瓦)等。但是在大陆地区由于官方废除已基本不使用,台湾仍在使用,一般人也明了其意思。注音:最早的注音方法是读若法和直注法。读若法就是用音近的字来注音,许慎的说文解字就采用这种注音方法,如“埻,射臬也,读若准”。直注法就是用另一个汉字来表明这个汉字的读音,如“女为说己者容”中,使用“说者曰悦”来进行注音。以上两种方法都有先天上不完善的地方,有些字没有同音字或是同音字过于冷僻,这就难以起到注音的作用,例如“袜音韈”等。魏晋时期发展出了反切法,据传是受使用拼音文字的梵文影响。汉字的发音可以通过反切法进行标注,即用第一个字的声母和第二个字的韵母和声调合拼来注音,使得所有汉字发音都有可能组合出来。如“练,朗甸切”,即“练”的发音是“朗”的声母与“甸”的韵母及声调所拼成。近代以来,又发展出了汉字形式的注音符号(俗称ㄅㄆㄇㄈ)以及很多拉丁字母注音方法。注音符号仍是台湾教学的一部分,而目前中国大陆最为广泛使用的是汉语拼音。由于汉字以本身表义为主,注音方面较为薄弱。这个特性使得上下千年的文献,不至于产生如同使用拼音文字的西方世界一样,用字措辞太悬殊的差距,但也造成推断古代声韵的难度。例如“庞”从“龙”而得声,但今日北京话前者读“páng”,后者为“lóng”。如何解释这样的差异,就是音韵学所探讨的课题。汉字与词语:汉字是汉文组成的最小单位。语素是汉文表意的最小单位,类比于英语的“词汇”和“词组”的总称。绝大多数汉字可以独立构成语素,比如“我”,类比于英语中的单一字母构成的词汇,比如“I”。现经白话文大多数词语都是由两个以上的汉字构成的,不过,和英语中“词汇”和“字母”的关系不同,语素的意思往往和其中各个汉字独立构成语素时的意思有相关性,因此相当程度上简化了记忆。词语包括语素和若干个语素形成的短语。汉字的高效率,体现在几百个基本象形字,可以合成表示天上地下的各种事物的上万汉字;几千个常用字,又可以轻松组合出数十万词语。不过,从另一方面来说,准确掌握这数十万词语的搭配形式和用法也成了一种负担。汉语常用词汇约为几万条,总词汇量约有百万条,虽然从数量上来说显得有些令人望而却步,但由于大多数汉字构词法的表意性,要基本掌握并非遥不可及。因此,仅就词汇而言,其学习难度并不高;相比之下,掌握同样数量外文词汇的记忆强度则要大得多。而从古文的角度来看,用字本义,比起五四白话文运动以降过度依赖词语,会来的精确且有效率,例如朱邦复先生就提畅精确使用汉字的复古作为。汉字的数量:汉字的数量并没有准确数字,日常所使用的汉字约为几千字。据统计,1000个常用字能覆盖约92%的书面资料,2000字可覆盖98%以上,3000字时已到99%,简体与繁体的统计结果相差不大。历史上出现过的汉字总数有8万多(也有6万多的说法),其中多数为异体字和罕用字。绝大多数异体字和罕用字已自然消亡或被规范掉,除古文之外一般只在人名、地名中偶尔出现。此外,继第一批简化字后,还有一批“二简字”,已被废除,但仍有少数字在社会上流行。汉字数量的首次统计是汉朝许慎在《说文解字》中进行的,共收录9353字。其后,南朝时顾野王所撰的《玉篇》据记载共收16917字,在此基础上修订的《大广益会玉篇》则据说有22726字。此后收字较多的是宋朝官修的《类篇》,收字31319个;另一部宋朝官修的《集韵》中收字53525个,曾经是收字最多的一部书。另外有些字典收字也较多,如清朝的《康熙字典》收字47035个;日本的《大汉和字典》收字48902个,另有附录1062个;台湾的《中文大字典》收字49905个;《汉语大字典》收字54678个。20世纪已出版的字数最多的是《中华字海》,收字85000个。在汉字计算机编码标准中,目前最大的汉字编码是台湾的国家标准CNS11643,目前(4.0)共收录可考证之繁简、日、韩语汉字共76,067个,但并不普及,只有在户政系统等少数环境使用。台港民间通用的大五码收录繁体汉字13053个。GB18030是中华人民共和国现时最新的内码字集,GBK收录简体、繁体及日语、韩语汉字20912个,而早期的GB2312收录简体汉字6763个。而Unicode的中日韩统一表意文字基本字集则收录汉字20902个,另有两个扩展区,总数亦高达七万多字。初期的汉字系统字数不足,很多事物以通假字表示,使文字的表述存在较大歧义。为完善表述的明确性,汉字经历了逐步复杂、字数大量增加的阶段。汉字数量的过度增加又引发了汉字学习的困难,单一汉字能表示的意义有限,于是有许多单一的汉语意义是用汉语词语表示,例如常见的双字词。目前汉语书写的发展多朝向造新词而非造新字。汉字汉字,是记录汉语的文字系统,并仍然或曾经在日语和朝鲜语、越南语中使用。汉字是世界上最古老的文字之一,拥有4500年以上的历史。狭义地说,它是汉族的文字;广义地言,它是汉字文化圈共同的文字。汉字是承载文化的重要工具,目前留有大量用汉字书写的典籍。不同的方言都使用汉字作为共同书写体系,因而汉字在历史上对中华文明的传播起到了重要作用,并成为东南亚文化圈形成的内在纽带。在汉字发展过程中,留下了大量诗词、对联等文化,并形成了独特的汉字书法艺术。一个汉字一般具有多种含义,也具有很强的组词能力,且很多汉字可独立成词。这导致了汉字极高的“使用效率”,2000左右常用字即可覆盖98%以上的书面表达方式。加之汉字表意文字的特性,汉字的阅读效率很高。汉字具备比字母文字更高的信息密度,因此,平均起来,同样内容的中文表达比其他任何字母语言的文字都短。目前的汉字体系分为繁体字和简体字,前者用于台湾、香港、澳门和北美的华人圈中,后者用于中国大陆和新加坡以及东南亚的华人社区。通常说来,两种汉字书写系统虽然有差异,常用汉字的个体差异不到25%。由于汉字书写复杂,“汉字落后论”的说法存在了很长时间,认为汉字是教育及信息化瓶颈,并有“汉字拉丁化”甚至废除汉字的推动行为。现在一般认为汉字也有突出优点,初始学习难度虽大,但掌握常用字后不存在类似海量英文单词的继续学习问题,且其表意特性也能充分调动人脑的学习能力。在计算机输入问题基本解决后,“汉字落后论”及“汉字拉丁化”已实际上逐渐被大多数人抛弃。目前汉字系统已经基本稳定,但汉字的规范化、生僻字的自然消亡仍在继续进行。
声明: 我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理,本站部分文字与图片资源来自于网络,转载是出于传递更多信息之目的,若有来源标注错误或侵犯了您的合法权益,请立即通知我们(管理员邮箱:daokedao3713@qq.com),情况属实,我们会第一时间予以删除,并同时向您表示歉意,谢谢!

 999+
999+ 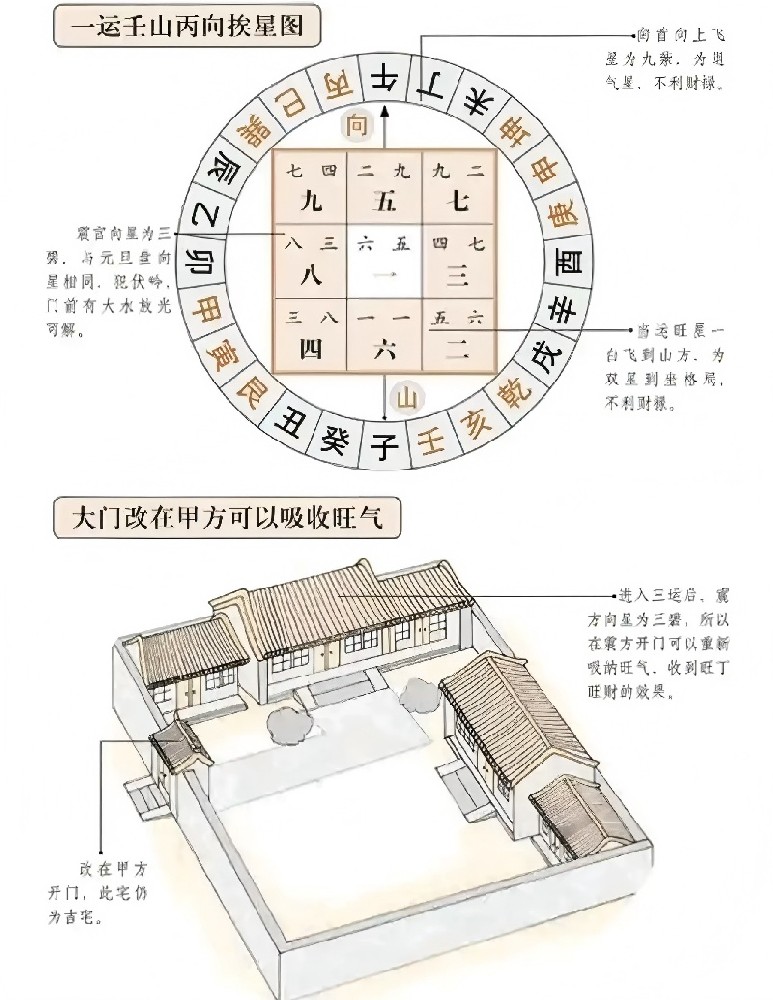 13
13  1843
1843  1922 1576 1961 1481
1922 1576 1961 1481  833 689
833 689  1540
1540 


本站内容仅供参考,不作为诊断及医疗依据,如有医疗需求,请务必前往正规医院就诊
祝由网所有文章及资料均为作者提供或网友推荐收集整理而来,仅供爱好者学习和研究使用,版权归原作者所有。
如本站内容有侵犯您的合法权益,请和我们取得联系,我们将立即改正或删除。
Copyright © 2022-2023 祝由师网 版权所有
邮箱:daokedao3713@qq.com
