
语音识别技术,也被称为自动语音识别,其目标是将人类的语音中的词汇内容转换为计算机可读的输入;原理是动态时间伸缩方法使用瞬间的、变动倒频,1963年Bogert et al出版了《回声的时序倒频分析》,通过交换字母顺序,他们用一个含义广泛的词汇定义了一个新的信号处理技术,倒频谱的计算通常使用快速傅立叶变换;从1975年起,隐马尔可夫模型变得很流行,运用隐马尔可夫模型的方法,频谱特征的统计变差得以测量,文本无关语音识别方法的例子有平均频谱法、矢量量化法和多变量自回归法;平均频谱法使用有利的倒频距离,语音频谱中
早期的训练语音模型的时候,我们需要标记每一帧的训练数据,这时候基本上是用传统的HMM和GMM做的。然后用标记了的数据去训练神经模型。端到端的方案是去处这部分非神经网络的处理阶段,而直接用CTC跟RNN来实现不需要标记到帧的训练数据来直接训练出语音模型,而不借助于其他(HMM,GMM)来训练神经网络模型。在传统的语音识别的模型中,我们对语音模型进行训练之前,往往都要将文本与语音进行严格的对齐操作。这样就有两点不太好:虽然现在已经有了一些比较成熟的开源对齐工具供大家使用,但是随着deep learning越来越火,有人就会想,能不能让我们的网络自己去学习对齐方式呢?因此CTC就应运而生啦。想一想,为什么CTC就不需要去对齐语音和文本呢?因为CTC它允许我们的神经网络在任意一个时间段预测label,只有一个要求:就是输出的序列顺序只要是正确的就ok啦~这样我们就不在需要让文本和语音严格对齐了,而且CTC输出的是整个序列标签,因此也不需要我们再去做一些后处理操作。对一段音频使用CTC和使用文本对齐的例子如下图所示:
声明: 我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理,本站部分文字与图片资源来自于网络,转载是出于传递更多信息之目的,若有来源标注错误或侵犯了您的合法权益,请立即通知我们(管理员邮箱:daokedao3713@qq.com),情况属实,我们会第一时间予以删除,并同时向您表示歉意,谢谢!

 999+
999+ 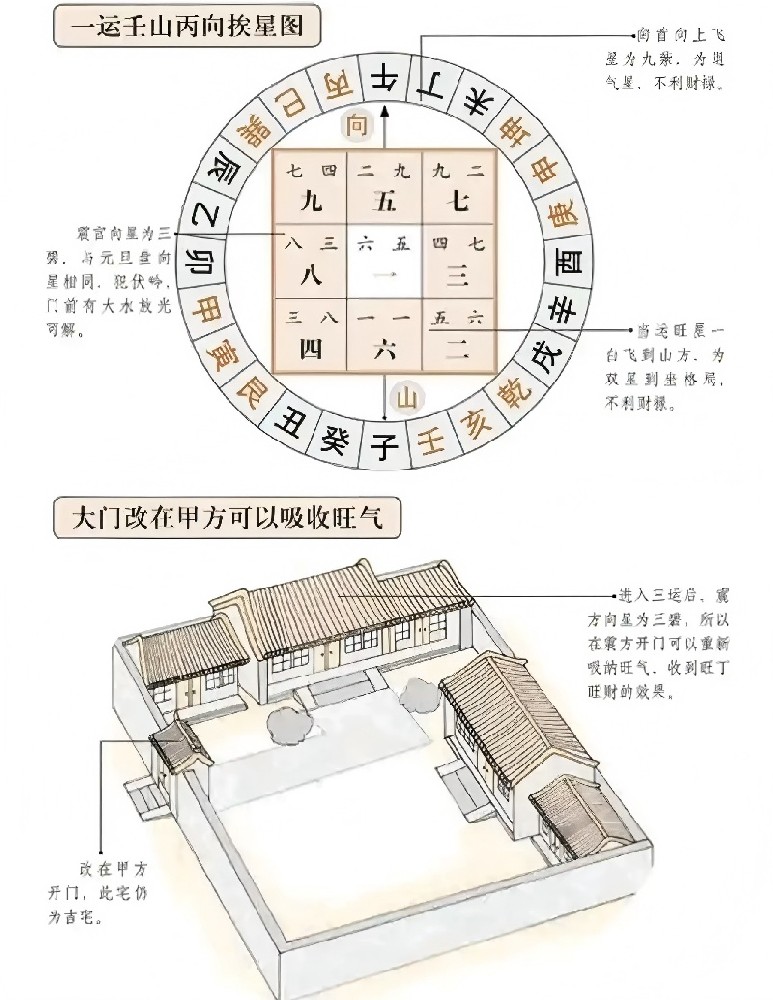 13
13  1843
1843  1922 1576 1961 1481
1922 1576 1961 1481  833 689
833 689  1540
1540 


本站内容仅供参考,不作为诊断及医疗依据,如有医疗需求,请务必前往正规医院就诊
祝由网所有文章及资料均为作者提供或网友推荐收集整理而来,仅供爱好者学习和研究使用,版权归原作者所有。
如本站内容有侵犯您的合法权益,请和我们取得联系,我们将立即改正或删除。
Copyright © 2022-2023 祝由师网 版权所有
邮箱:daokedao3713@qq.com
