
面向对象遥感图像分类,处理的最小单元不再是像元,而是含有更多语义信息的多个相邻像元组成的影像对象,在分类时更多的是利用对象的几何信息以及影像对象之间的语义对象、纹理信息、拓扑关系,而不仅仅是单个对象的光谱信息。
杨大志 付洛玲 段嵘峰 曹千红 管相荣
(河南省国土资源厅信息中心,郑州,450003)
摘要:本文采用面向对象分类的方法,使用专业遥感图像分类软件eCognition4.0,以河南省临颍县为研究区,对处理后的临颍县SPOT5影像进行多层次分割及合并,根据分类体系定义相应知识库,进行土地利用信息提取研究,探讨该方法在高空间分辨率遥感影像应用于土地利用/土地覆被自动分类中的应用潜能,为高分辨率影像用于土地利用分类信息提取提供新技术手段。
关键词:eCognition;SPOT5;自动分类;土地利用
土地资源利用状况调查、土地资源动态监测是土地管理工作的一个重要内容。近年来,随着空间遥感技术的发展,高分辨率遥感影像在土地资源调查、土地资源动态监测等领域中的应用日益广泛。高分辨率遥感数据与多光谱和高光谱分辨率数据相比,具有空间信息丰富、地物几何结构和纹理信息更加明显、波段较少的特点。对于高分辨率的遥感影像来说,利用传统的面向像元的图像分类方法来提取土地利用分类信息,易造成分类精度低,空间数据大量冗余以及资源的浪费[1~2]。实际上,靠传统的面向像元的遥感图像分类法来提取土地利用信息已不能满足实际运用的要求。因此,基于高分辨率遥感影像土地利用分类信息提取必须根据其特点采取新的技术方法,建立起图像数据与目标特性之间的物理—机理联系,而不仅仅是统计联系,才能充分挖掘高分辨率遥感影像所包含的信息,这是高分辨率卫星影像信息处理成败的关键[3]。面向对象分类技术作为一种新的遥感影像很好地解决了这个问题,而eCognition软件正是基于面向对象方法的影像分类技术。本文就是基于该软件以河南省临颍县土地利用分类信息提取为例对该方法进行了探讨。
1 研究区概况和资料基础
研究选取河南省临颍县作为研究区。临颍县位于河南省中部,颍河上游,属漯河市,面积821km2,人口65.76 万,辖15个乡镇,362个行政村。临颍县地处颍河冲积平原,西北部较高,东南部稍低。图1是河南省临颍县SPOT5遥感影像图。
本研究主要以下述资料为研究基础。
1.1 影像数据
本次遥感图像分类采用数据为SPOT5 (2.5 m分辨率)影像数据,景带号为279/281和279/282,接收时间为2004年9月。两景数据采用Erdas 8.7软件进行处理,通过配准校正融合,选择克拉索夫斯基椭球体和高斯—克吕格投影,通过裁切,得到临颍县遥感影像数据(见图1)。
图1 河南省临颍县 SPOT5 遥感影像图
1.2 矢量数据
近年的土地利用数据库数据。
1.3 其他资料
与研究区有关的行政区划、农、林等方面的文献资料。
通过近年的土地利用数据库数据和影像数据研究可以发现临颍县土地利用类型较丰富,主要以农用地为主,地物类型比较全面,是研究土地利用/土地覆被的较好选择。
2 面向对象分类方法简介
面向对象的分类方法是一种智能化的自动影像分析方法,它的分析单元不再是单个像素,而是由若干个像素组成的像素群,即目标对象[4]。目标对象比单个像素更具有实际意义,特征的定义和分类均是基于目标对象进行的。通常面向对象的分类方法包括两个步骤:多分辨率分割和模糊逻辑分类[5]。
eCognition软件采用面向对象的遥感影像解译思想。首先根据像元光谱信息、局部区域纹理信息以及形状和尺度参数自动将影像分割为若干相对同质的区域,称为影像对象(Image objects),为下一步分类提供信息载体和构建基础[6],所有后续的分类工作都基于这些影像对象进行,分类结果避免了斑点噪声而具有很好的整体性,改变了以往面向像素进行分类的传统。同时,软件提供最邻近法和模糊隶属度函数两种解译方法。
本研究就是采用面向对象的分类方法,以eCognition 中membership function (隶属度函数)为主,模仿目视解译过程,从遥感信息机理与地学规律的综合分析入手,综合其他辅助信息进行分类。通过对辅助资料、外业调查成果以及软件的学习得到了临颍县各类典型地物分类的知识,并以相应的形式表示这些知识,集成影像亮度值、亮度值关系和几何形状以及纹理、邻近关系等特征,对试验区土地利用/覆被进行分类。
3 分类体系和技术流程
3.1 分类体系
根据临颍县土地利用实际情况,参照历年土地利用分类标准,本次信息提取分类采取的分类体系如图2所示。
3.2 技术流程
使用eCognition软件对研究区SPOT5影像数据进行土地利用信息提取研究分如下几步进行:①把处理好的影像数据输入到软件中,定制分割参数,对其执行分割,生成影像对象;②根据研究区地物类型创建分类层次结构;③确定合适的分类方法(包括最邻近法和模糊隶属度函数两种方法),选取相应地物类型样本或者分类特征,构建知识库,执行分类,并可根据目视解译结果和事先准备的调查区资料对分类结果进行人工干预,进一步提高分类精度;④对分类结果进行分类精度评价;⑤把分类结果输出,输出的格式可以为所需要的相应的矢量格式或栅格格式。本研究的技术流程如图3所示。
图2 研究区地物类型
图3 研究技术流程图
4 主要分类过程
4.1 定制分割参数
分割参数的定制相当重要,它关系到每一个分类对象的大小,直接影响到最后的分类结果。通过多次试验,本次分类决定采用多层次分割的方法进行:水体和非水体信息的提取以分割参数为80进行,其他参数均为默认;分类体系中其他类别信息的提取在首次分割基础上,以分割参数为65,其他参数也为默认对非水体进行多重分割,来进行其他地物类型的分类。
4.2 制定分类策略,创建类层次结构
在进行分类之前,首先要参照研究区地物类型,分析每种地物类型特征及其相互之间的关系,制定合适的分类策略,创建类层次结构。可利用的研究对象属性特征包括色调、形状、面积/大小和纹理等特征,各对象之间关系包括与父对象之间、与子对象之间以及与邻对象之间的关系三种类型。对象属性特征选取正确与否及其在多大程度上被正确表达对分类结果有着重要影响,它决定了最后分类正确与否和其精度。面向对象的分类方法可以模仿人类大脑认知过程,充分利用每种地物类型特征,按照由简单到困难的顺序逐步剥离提取分类体系中每种地物信息。通过研究本次分类所要提取信息自身特征及其相互之间关系,制定本次分类的分类策略,创建了类层次结构,如图4所示。
图4 类层次结构示意图
4.3 分类特征的选取
根据创建的类层次结构,选取合适的对象属性,对对象属性进行定义,提取出相应对象的土地利用信息。本次分类采用以下几步进行:
(1)提取水体信息 分割参数设为80,对影像进行分割,分割后,在整个研究区均匀选取样本,采用标准最邻近方法(Standard Nearest Neighbor)对遥感影像进行分类(类似于监督分类),提取水体信息。在此基础上,依据水体的形状特征,把水体分为河流水面和坑塘水面两类。根据实验,长宽比大于3是河流,小于3的是坑塘。
(2)提取植被信息,并进一步把植被分为耕地和林地 首先把提取出的水体信息保护起来,在首次分割的基础上对非水体进行再分割,分割参数设为65,其他参数为默认值,把非水体分为植被和非植被两类,然后根据耕地和林地的不同特征把其信息提取出来。
(3)对非植被信息进一步细分,从中提取出主要交通道路、城镇居民点工矿和裸地(已收获耕地) 信息 首先从非植被信息中提取出交通道路和非交通道路信息,然后把非交通道路细分为裸地(已收获耕地)和城镇居民点工矿两类。
此时,分类体系中的所有类别信息已经全部提取出来,可根据实际情况对分类结果进行手工编辑,进一步删除一些过小对象和纠正一些错分信息。当分得的各类信息结果都比较满意后,进行基于分类的融合,把小对象合并为大的对象,通过手工编辑和基于分类的融合后,得到最终分类结果如图5所示。
图5 遥感影像分类结果图
4.4 分类精度评价
得到分类结果后,要根据分类得到的结果进行分类精度评价。评价采用如下方法进行:在分割后的影像上均匀随机选取每个地类的目标对象,选取的目标对象数目根据分类结果得到的每个地类的目标对象数目而定,进行自动统计,得到统计结果。统计结果如表1所示。
表1 分类结果精度评价表
通过分类结果精度评价表可以发现,自动分类的最后分类精度超过了80%,这对于研究区来讲,分类结果还是比较令人满意的。同时,根据统计结果可以得到如下结论:耕地、城镇居民点、坑塘、河流信息提取的效果较好;相对而言,裸地和道路信息提取比较困难;林地信息由于同耕地信息相近,提取起来也有相当的难度,还有待于今后进一步研究。
通过研究表明,采用面向对象方法进行图像解译和信息的自动提取与面向像元方法相比具有较强优势。面向对象的分类方法可以灵活运用地物本身的几何信息和结构信息,纹理信息以及上下层关系信息、邻近关系信息等,更主要的是可以加载人的思维,构建知识库,从而提高了分类的精度,为各种不同地物的分类提供了更多的依据,比如通过影像的形状和纹理特征可以有效地识别河流、道路、建筑物的形状。利用eCognition对高分辨率遥感图像进行土地利用自动分类,快速简便,而且能够达到较高精度,节省了大量的人力物力,为大面积土地利用调查和监测提供了新的科学方法。
参考文献
丁晓英.eCognition在土地利用项目中的应用[J].测绘与空间地理信息,2005,28 (6):116~120
刘亚岚,阎守邕,王涛等.遥感图像分区自动分类方法研究[J].遥感学报,2002,6 (5):357~362
孙晓霞,张继贤,刘正军.利用面向对象的分类方法从IKONOS全色影像中提取河流和道路[J].测绘科学,2006,31 (1):62~63
eCognition 3 Made in Germany [Z]
Sun Xiaoxia.An object-oriented classification method on high resolution satellite data [Z].ACRS2004,Istanbul
杜凤兰.面向对象的地物分类方法分析与评价[J].遥感技术与应用,2004,19 (1):20~23
含义:
传统的遥感变化监测和信息提取主要是基于中低分辨率的遥感卫星数据或航片,通过目视判读或是基于像素的计算机分类方法,信息提取的精度和效率不能兼顾。
面向对象的遥感高空间分辨率影像空间信息更加丰富,地物目标细节信息表达的更加清楚。
从分类技术角度来看
由于受空间分辨率的制约,传统的遥感影像信息提取只能依靠影像的光谱信息,且是在像素层次上的分类;
而面向对象的遥感高空间分辨率影像虽然结构、纹理等信息非常突出,但光谱信息不足(波段较少)。所以仅仅依靠像素的光谱信息进行分类,着眼于局部像素而忽略邻近整片图班的纹理、结构等信息,必然会造成分类精度的降低。
常用的遥感数据的专题分类方法有多种,从分类判别决策方法的角度可以分为统计分类器、神经网络分类器、专家系统分类器等;从是否需要训练数据方面,又可以分为监督分类器和非监督分类器。
一、统计分类方法
统计分类方法分为非监督分类方法和监督分类方法。非监督分类方法不需要通过选取已知类别的像元进行分类器训练,而监督分类方法则需要选取一定数量的已知类别的像元对分类器进行训练,以估计分类器中的参数。非监督分类方法不需要任何先验知识,也不会因训练样本选取而引入认为误差,但非监督分类得到的自然类别常常和研究感兴趣的类别不匹配。相应地,监督分类一般需要预先定义分类类别,训练数据的选取可能会缺少代表性,但也可能在训练过程中发现严重的分类错误。
1.非监督分类器
非监督分类方法一般为聚类算法。最常用的聚类非监督分类方法是 K-均值(K-Means Algorithm)聚类方法(Duda and Hart,1973)和迭代自组织数据分析算法(ISODATA)。其算法描述可见于一般的统计模式识别文献中。
一般通过简单的聚类方法得到的分类结果精度较低,因此很少单独使用聚类方法进行遥感数据专题分类。但是,通过对遥感数据进行聚类分析,可以初步了解各类别的分布,获取最大似然监督分类中各类别的先验概率。聚类分析最终的类别的均值矢量和协方差矩阵可以用于最大似然分类过程(Schowengerdt,1997)。
2.监督分类器
监督分类器是遥感数据专题分类中最常用的一种分类器。和非监督分类器相比,监督分类器需要选取一定数量的训练数据对分类器进行训练,估计分类器中的关键参数,然后用训练后的分类器将像元划分到各类别。监督分类过程一般包括定义分类类别、选择训练数据、训练分类器和最终像元分类四个步骤(Richards,1997)。每一步都对最终分类的不确定性有显著影响。
监督分类器又分为参数分类器和非参数分类器两种。参数分类器要求待分类数据满足一定的概率分布,而非参数分类器对数据的概率分布没有要求。
遥感数据分类中常用的分类器有最大似然分类器、最小距离分类器、马氏距离分类器、K-最近邻分类器(K-Nearest neighborhood classifier,K-NN)以及平行六面体分类器(parallelepiped classifier)。最大似然、最小距离和马氏距离分类器在第三章已经详细介绍。这里简要介绍 K-NN 分类器和平行六面体分类器。
K-NN分类器是一种非参数分类器。该分类器的决策规则是:将像元划分到在特征空间中与其特征矢量最近的训练数据特征矢量所代表的类别(Schowengerdt,1997)。当分类器中 K=1时,称为1-NN分类器,这时以离待分类像元最近的训练数据的类别作为该像元的类别;当 K >1 时,以待分类像元的 K 个最近的训练数据中像元数量最多的类别作为该像元的类别,也可以计算待分类像元与其 K 个近邻像元特征矢量的欧氏距离的倒数作为权重,以权重值最大的训练数据的类别作为待分类像元的类别。Hardin,(1994)对 K-NN分类器进行了深入的讨论。
平行六面体分类方法是一个简单的非参数分类算法。该方法通过计算训练数据各波段直方图的上限和下限确定各类别像元亮度值的范围。对每一类别来说,其每个波段的上下限一起就形成了一个多维的盒子(box)或平行六面体(parallelepiped)。因此 M 个类别就有M 个平行六面体。当待分类像元的亮度值落在某一类别的平行六面体内时,该像元就被划分为该平行六面体代表的类别。平行六面体分类器可以用图5-1中两波段的遥感数据分类问题来表示。图中的椭圆表示从训练数据估计的各类别亮度值分布,矩形表示各类别的亮度值范围。像元的亮度落在哪个类别的亮度范围内,就被划分为哪个类别。
图5-1 平行六面体分类方法示意图
3.统计分类器的评价
各种统计分类器在遥感数据分类中的表现各不相同,这既与分类算法有关,又与数据的统计分布特征、训练样本的选取等因素有关。
非监督聚类算法对分类数据的统计特征没有要求,但由于非监督分类方法没有考虑任何先验知识,一般分类精度比较低。更多情况下,聚类分析被作为非监督分类前的一个探索性分析,用于了解分类数据中各类别的分布和统计特征,为监督分类中类别定义、训练数据的选取以及最终的分类过程提供先验知识。在实际应用中,一般用监督分类方法进行遥感数据分类。
最大似然分类方法是遥感数据分类中最常用的分类方法。最大似然分类属于参数分类方法。在有足够多的训练样本、一定的类别先验概率分布的知识,且数据接近正态分布的条件下,最大似然分类被认为是分类精度最高的分类方法。但是当训练数据较少时,均值和协方差参数估计的偏差会严重影响分类精度。Swain and Davis(1978)认为,在N维光谱空间的最大似然分类中,每一类别的训练数据样本至少应该达到10×N个,在可能的条件下,最好能达到100×N以上。而且,在许多情况下,遥感数据的统计分布不满足正态分布的假设,也难以确定各类别的先验概率。
最小距离分类器可以认为是在不考虑协方差矩阵时的最大似然分类方法。当训练样本较少时,对均值的估计精度一般要高于对协方差矩阵的估计。因此,在有限的训练样本条件下,可以只估计训练样本的均值而不计算协方差矩阵。这样最大似然算法就退化为最小距离算法。由于没有考虑数据的协方差,类别的概率分布是对称的,而且各类别的光谱特征分布的方差被认为是相等的。很显然,当有足够训练样本保证协方差矩阵的精确估计时,最大似然分类结果精度要高于最小距离精度。然而,在训练数据较少时,最小距离分类精度可能比最大似然分类精度高(Richards,1993)。而且最小距离算法对数据概率分布特征没有要求。
马氏距离分类器可以认为是在各类别的协方差矩阵相等时的最大似然分类。由于假定各类别的协方差矩阵相等,和最大似然方法相比,它丢失了各类别之间协方差矩阵的差异的信息,但和最小距离法相比较,它通过协方差矩阵保持了一定的方向灵敏性(Richards,1993)。因此,马氏距离分类器可以认为是介于最大似然和最小距离分类器之间的一种分类器。与最大似然分类一样,马氏距离分类器要求数据服从正态分布。
K-NN分类器的一个主要问题是需要很大的训练数据集以保证分类算法收敛(Devijver and Kittler,1982)。K-NN分类器的另一个问题是,训练样本选取的误差对分类结果有很大的影响(Cortijo and Blanca,1997)。同时,K-NN分类器的计算复杂性随着最近邻范围的扩大而增加。但由于 K-NN分类器考虑了像元邻域上的空间关系,和其他光谱分类器相比,分类结果中“椒盐现象”较少。
平行六面体分类方法的优点在于简单,运算速度快,且不依赖于任何概率分布要求。它的缺陷在于:首先,落在所有类别亮度值范围之外的像元只能被分类为未知类别;其次,落在各类别亮度范围重叠区域内的像元难以区分其类别(如图5-1所示)。
各种统计分类方法的特点可以总结为表5-1。
二、神经网络分类器
神经网络用于遥感数据分类的最大优势在于它平等地对待多源输入数据的能力,即使这些输入数据具有完全不同的统计分布,但是由于神经网络内部各层大量的神经元之间连接的权重是不透明的,因此用户难以控制(Austin,Harding and Kanellopoulos et al.,1997)。
神经网络遥感数据分类被认为是遥感数据分类的热点研究领域之一(Wilkinson,1996;Kimes,1998)。神经网络分类器也可分为监督分类器和非监督分类器两种。由于神经网络分类器对分类数据的统计分布没有任何要求,因此神经网络分类器属于非参数分类器。
遥感数据分类中最常用的神经网络是多层感知器模型(multi-layer percep-tron,MLP)。该模型的网络结构如图5-2所示。该网络包括三层:输入层、隐层和输出层。输入层主要作为输入数据和神经网络输入界面,其本身没有处理功能;隐层和输出层的处理能力包含在各个结点中。输入的结构一般为待分类数据的特征矢量,一般情况下,为训练像元的多光谱矢量,每个结点代表一个光谱波段。当然,输入结点也可以为像元的空间上下文信息(如纹理)等,或多时段的光谱矢量(Paola and Schowengerdt,1995)。
表5-1 各种统计分类器比较
图5-2 多层感知器神经网络结构
对于隐层和输出层的结点来说,其处理过程是一个激励函数(activation function)。假设激励函数为f(S),对隐层结点来说,有:
遥感信息的不确定性研究
其中,pi为隐层结点的输入;hj为隐层结点的输出;w为联接各层神经之间的权重。
对输出层来说,有如下关系:
遥感信息的不确定性研究
其中,hj为输出层的输入;ok为输出层的输出。
激励函数一般表达为:
遥感信息的不确定性研究
确定了网络结构后,就要对网络进行训练,使网络具有根据新的输入数据预测输出结果的能力。最常用的是后向传播训练算法(Back-Propagation)。这一算法将训练数据从输入层进入网络,随机产生各结点连接权重,按式(5-1)(5-2)和(5-3)中的公式进行计算,将网络输出与预期的结果(训练数据的类别)相比较并计算误差。这个误差被后向传播的网络并用于调整结点间的连接权重。调整连接权重的方法一般为delta规则(Rumelhart,et al.,1986):
遥感信息的不确定性研究
其中,η为学习率(learning rate);δk为误差变化率;α为动量参数。
将这样的数据的前向和误差后向传播过程不断迭代,直到网络误差减小到预设的水平,网络训练结束。这时就可以将待分类数据输入神经网络进行分类。
除了多层感知器神经网络模型,其他结构的网络模型也被用于遥感数据分类。例如,Kohonen自组织网络被广泛用于遥感数据的非监督聚类分析(Yoshida et al.,1994;Schaale et al.,1995);自适应共振理论(Adaptive Resonance Theory)网络(Silva,S and Caetano,M.1997)、模糊ART图(Fuzzy ART Maps)(Fischer,M.M and Gopal,S,1997)、径向基函数(骆剑承,1999)等也被用于遥感数据分类。
许多因素影响神经网络的遥感数据分类精度。Foody and Arora(1997)认为神经网络结构、遥感数据的维数以及训练数据的大小是影响神经网络分类的重要因素。
神经网络结构,特别是网络的层数和各层神经元的数量是神经网络设计最关键的问题。网络结构不但影响分类精度,而且对网络训练时间有直接影响(Kavzoglu and Mather,1999)。对用于遥感数据分类的神经网络来说,由于输入层和输出层的神经元数目分别由遥感数据的特征维数和总的类别数决定的,因此网络结构的设计主要解决隐层的数目和隐层的神经元数目。一般过于复杂的网络结构在刻画训练数据方面较好,但分类精度较低,即“过度拟合”现象(over-fit)。而过于简单的网络结构由于不能很好的学习训练数据中的模式,因此分类精度低。
网络结构一般是通过实验的方法来确定。Hirose等(1991)提出了一种方法。该方法从一个小的网络结构开始训练,每次网络训练陷入局部最优时,增加一个隐层神经元,然后再训练,如此反复,直到网络训练收敛。这种方法可能导致网络结构过于复杂。一种解决办法是每当认为网络收敛时,减去最近一次加入的神经元,直到网络不再收敛,那么最后一次收敛的网络被认为是最优结构。这种方法的缺点是非常耗时。“剪枝法”(pruning)是另一种确定神经网络结构的方法。和Hirose等(1991)的方法不同,“剪枝法”从一个很大的网络结构开始,然后逐步去掉认为多余的神经元(Sietsma and Dow,1988)。从一个大的网络开始的优点是,网络学习速度快,对初始条件和学习参数不敏感。“剪枝”过程不断重复,直到网络不再收敛时,最后一次收敛的网络被认为最优(Castellano,Fanelli and Pelillo,1997)。
神经网络训练需要训练数据样本的多少随不同的网络结构、类别的多少等因素变化。但是,基本要求是训练数据能够充分描述代表性的类别。Foody等(1995)认为训练数据的大小对遥感分类精度有显著影响,但和统计分类器相比,神经网络的训练数据可以比较少。
分类变量的数据维对分类精度的影响是遥感数据分类中的普遍问题。许多研究表明,一般类别之间的可分性和最终的分类精度会随着数据维数的增大而增高,达到某一点后,分类精度会随数据维的继续增大而降低(Shahshahani and Landgrebe,1994)。这就是有名的Hughes 现象。一般需要通过特征选择去掉信息相关性高的波段或通过主成分分析方法去掉冗余信息。分类数据的维数对神经网络分类的精度同样有明显影响(Battiti,1994),但Hughes 现象没有传统统计分类器中严重(Foody and Arora,1997)。
Kanellopoulos(1997)通过长期的实践认为一个有效的ANN模型应考虑以下几点:合适的神经网络结构、优化学习算法、输入数据的预处理、避免振荡、采用混合分类方法。其中混合模型包括多种ANN模型的混合、ANN与传统分类器的混合、ANN与知识处理器的混合等。
三、其他分类器
除了上述统计分类器和神经网络分类器,还有多种分类器被用于遥感图像分类。例如模糊分类器,它是针对地面类别变化连续而没有明显边界情况下的一种分类器。它通过模糊推理机制确定像元属于每一个类别的模糊隶属度。一般的模糊分类器有模糊C均值聚类法、监督模糊分类方法(Wang,1990)、混合像元模型(Foody and Cox,1994;Settle and Drake,1993)以及各种人工神经网络方法等(Kanellopoulos et al.,1992;Paola and Schowengerdt,1995)。由于模糊分类的结果是像元属于每个类别的模糊隶属度,因此也称其为“软分类器”,而将传统的分类方法称为“硬分类器”。
另一类是上下文分类器(contextual classifier),它是一种综合考虑图像光谱和空间特征的分类器。一般的光谱分类器只是考虑像元的光谱特征。但是,在遥感图像中,相邻的像元之间一般具有空间自相关性。空间自相关程度强的像元一般更可能属于同一个类别。同时考虑像元的光谱特征和空间特征可以提高图像分类精度,并可以减少分类结果中的“椒盐现象”。当类别之间的光谱空间具有重叠时,这种现象会更明显(Cortijo et al.,1995)。这种“椒盐现象”可以通过分类的后处理滤波消除,也可以通过在分类过程中加入代表像元邻域关系的信息解决。
在分类过程中可以通过不同方式加入上下文信息。一是在分类特征中加入图像纹理信息;另一种是图像分割技术,包括区域增长/合并常用算法(Ketting and Landgrebe,1976)、边缘检测方法、马尔可夫随机场方法。Rignot and Chellappa(1992)用马尔可夫随机场方法进行SAR图像分类,取得了很好的效果,Paul Smits(1997)提出了保持边缘细节的马尔可夫随机场方法,并用于SAR图像的分类;Crawford(1998)将层次分类方法和马尔可夫随机场方法结合进行SAR图像分类,得到了更高的精度;Cortijo(1997)用非参数光谱分类对遥感图像分类,然后用ICM算法对初始分类进行上下文校正。
声明: 我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理,本站部分文字与图片资源来自于网络,转载是出于传递更多信息之目的,若有来源标注错误或侵犯了您的合法权益,请立即通知我们(管理员邮箱:daokedao3713@qq.com),情况属实,我们会第一时间予以删除,并同时向您表示歉意,谢谢!

 999+
999+ 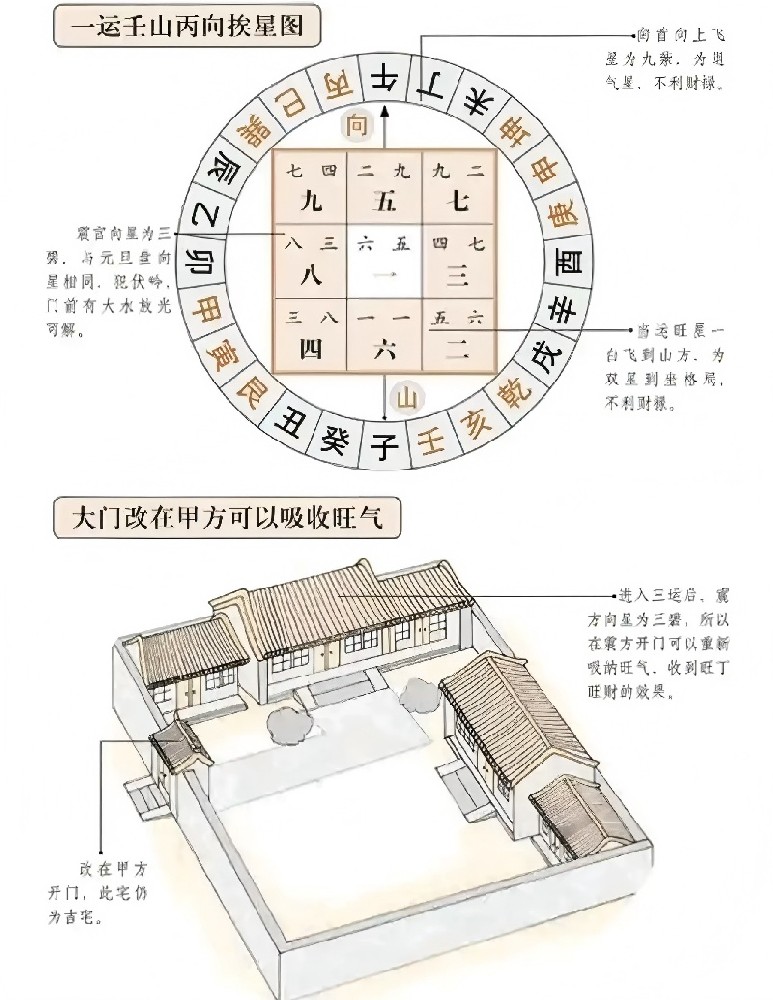 13
13  1843
1843  1922 1576 1961 1481
1922 1576 1961 1481  833 689
833 689  1540
1540 


本站内容仅供参考,不作为诊断及医疗依据,如有医疗需求,请务必前往正规医院就诊
祝由网所有文章及资料均为作者提供或网友推荐收集整理而来,仅供爱好者学习和研究使用,版权归原作者所有。
如本站内容有侵犯您的合法权益,请和我们取得联系,我们将立即改正或删除。
Copyright © 2022-2023 祝由师网 版权所有
邮箱:daokedao3713@qq.com
